机器学习笔记
本文作者:李德强
第二节 信息增益
信息增益是度量样本集合纯度最常用的一种指标,我们通常使用“香农熵”来计算训练样本中每一个特征的熵值:
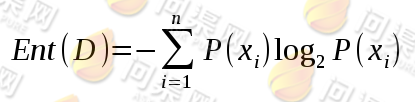
其中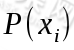 为训练样本中某个特征第i种取值在整个训练样本中出现的概率。例如在西瓜好坏判断训练样本中对于“色泽”特征做香农熵计算时,训练样本总数为10,而“青绿”出现的次数为4,乌黑和浅白出现的次数都为3,则它们出现的概率分别为:
为训练样本中某个特征第i种取值在整个训练样本中出现的概率。例如在西瓜好坏判断训练样本中对于“色泽”特征做香农熵计算时,训练样本总数为10,而“青绿”出现的次数为4,乌黑和浅白出现的次数都为3,则它们出现的概率分别为:
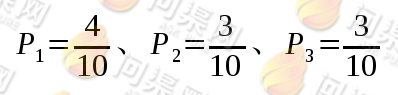
对于“色泽”这个特征来说,它的香农熵计算方法为:
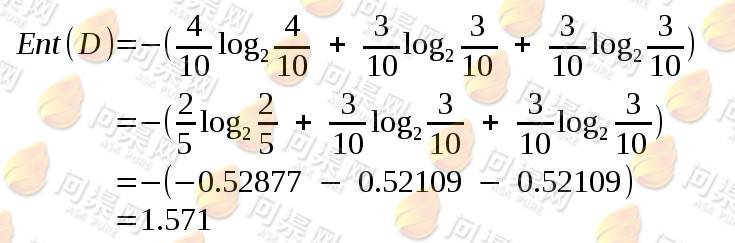
同样的,对“敲声”和“纹理”分别做香农熵计算得到的值分别为1.4855和0.97095。于是我们需要选取信息增益最大的特征做为当前数据的划分方法,即首先对“色泽”来进行划分。分别得到了三个不同的训练子集,然后再分别对不同的子集做递归的决策树划分。
Copyright © 2015-2023 问渠网 辽ICP备15013245号