机器学习笔记
本文作者:李德强
第一节 问题的提出
我们来思考这样的一个问题,在一个房间里装有n个话筒,这n个话筒分布在不同的角落里,同时房间中还有有n个人在说话。这n个话筒在房间里记录了这n个人的说话内容,随着时间的推移,我们得到了这样的数据:
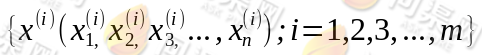
其中i表示采样的时间顺序,我们一共得到了m组样本,每一组样本都是n维的。请大家注意这样一个问题,每一个话筒所记录的声音都是这n个人同时发出的混合声音。也就是说每一个话筒记录的样本中不是只记录一个人的声音,而是n个人的混合声音。如下图:
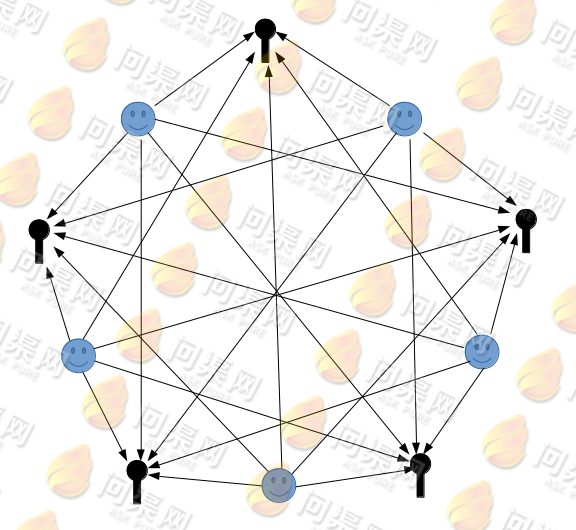
对于某一个话筒来说,它所记录的混合声音中某几个人的声音大(距离较近),有几个人的声音小(距离较远),于是我们的问题就很明确了,我们能否从这n个话筒中记录的样本中分离出每一个人的说话内容呢?我们假设有n个信号源:
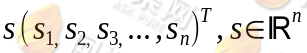
这个信号源s有n维,每一维都是一个人的声音信号,我们假设每个人所发出的声音信号都是独立的。设A为一个未知的混合矩阵,用于与信号s进行叠加并得到x,也就是话筒采集混合信号的过程:
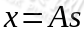
而对于矩阵x来说,它的每一个列向量:
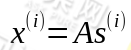
Copyright © 2015-2023 问渠网 辽ICP备15013245号